
 06.搭建一套源生hadoop、Spark、Flink集群3-Hive安装原创
06.搭建一套源生hadoop、Spark、Flink集群3-Hive安装原创
# 搭建一套源生Hadoop、Spark、Flink集群
本文记录如何搭建原生集群。
# 一、安装Hive
将以下安装包上传到/opt/softwares/mysql:
01_mysql-community-common-5.7.16-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm mysql-connector-java-5.1.27-bin.jar
# 1.安装Mysql
# 卸载系统自带mysql
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
sudo yum remove mysql-libs
# 安装mysql
sudo yum install libaio
sudo yum -y install autoconf
cd /opt/softwares/mysql
sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
# 启动mysql
sudo systemctl enable mysqld
sudo systemctl start mysqld
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.配置Mysql
# 查看密码
sudo cat /var/log/mysqld.log | grep password
# 登录
mysql -uroot -p'password'
2
3
4
登录后配置Mysql
# 初始设置复杂密码
set password=password("Qs23=zs32");
# 修改密码复杂度要求
set global validate_password_length=4;
set global validate_password_policy=0;
# 设置简单密码
set password=password("root");
use mysql;
select user, host from user;
# 修改user表,把Host表内容修改为% 用于远程连接
update user set host="%" where user="root";
# 刷新
flush privileges;
quit;
2
3
4
5
6
7
8
9
10
11
12
13
14
使用DataGrip等工具连接mysql,测试能否正常使用。
# 3.配置Hive
# 解压
tar -zxvf /opt/softwares/apache-hive-4.0.0-bin.tar.gz -C /opt/apache/
# 解决jar包冲突
cd /opt/apache/apache-hive-4.0.0-bin/lib
mv log4j-slf4j-impl-2.18.0.jar log4j-slf4j-impl-2.18.0.jar.bak
# 拷贝MySQL的JDBC驱动
cp /opt/softwares/mysql/mysql-connector-java-5.1.27-bin.jar /opt/apache/apache-hive-4.0.0-bin/lib/.
# 程序分发
xsync /opt/apache/apache-hive-4.0.0-bin/
# 配置环境变量
su root
vim /etc/profile.d/my_env.sh
---------------------------------
# HIVE配置
export HIVE_VERSION=4.0.0
export HIVE_HOME=/opt/apache/apache-hive-4.0.0-bin
export PATH=$HIVE_HOME/bin:$PATH
---------------------------------
# 配置分发
xsync /etc/profile.d/my_env.sh
xcall source /etc/profile.d/my_env.sh
# 配置Metastore到MySQL
cd $HIVE_HOME/conf
vim hive-site.xml
---------------------------------
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bd181:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--告知Spark Hive的MetaStore在哪-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://bd183:9083</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bd183</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://bd181:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎 Hive4.0取消了对Spark引擎的支持,如果是Hive 3可开启此配置-->
<!-- <property>
<name>hive.execution.engine</name>
<value>spark</value>
</property> -->
<!--Hive 和 Spark 连接超时时间-->
<!-- <property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property> -->
</configuration>
---------------------------------
# 文件分发
xsync $HIVE_HOME/conf/hive-site.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
初始化元数据库:
# 建立元数据库
mysql -uroot -proot
create database metastore;
quit;
# 执行hive初始化
schematool -initSchema -dbType mysql -verbose
# 修改Hive元数据库中存储注释的字段的字符集为utf-8,解决中文乱码
# 字段注释
use metastore;
alter table metastore.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
# 表注释
alter table metastore.TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
2
3
4
5
6
7
8
9
10
11
12
配置HiveServer跟MetaStore服务脚本hiveservices.sh:
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
连接hive:在Hive 4.0.0中,Hive CLI已经被弃用,取而代之的是Beeline。所以,当你启动Hive 4.0.0时,你会默认进入Beeline命令行界面,而不是Hive CLI。如果你想使用Hive CLI,你可以考虑降低Hive的版本,或者在Hive 4.0.0中使用Beeline命令行。
# 用eddie用户登录hive
beeline -u "jdbc:hive2://bd183:10000/default" -n eddie -p 密码
2
用DataGrip连接并测试:
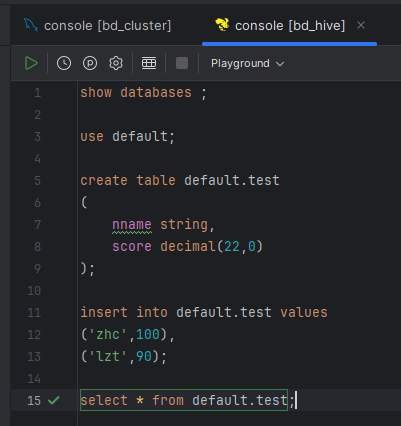
查看Yarn、JobHistory:
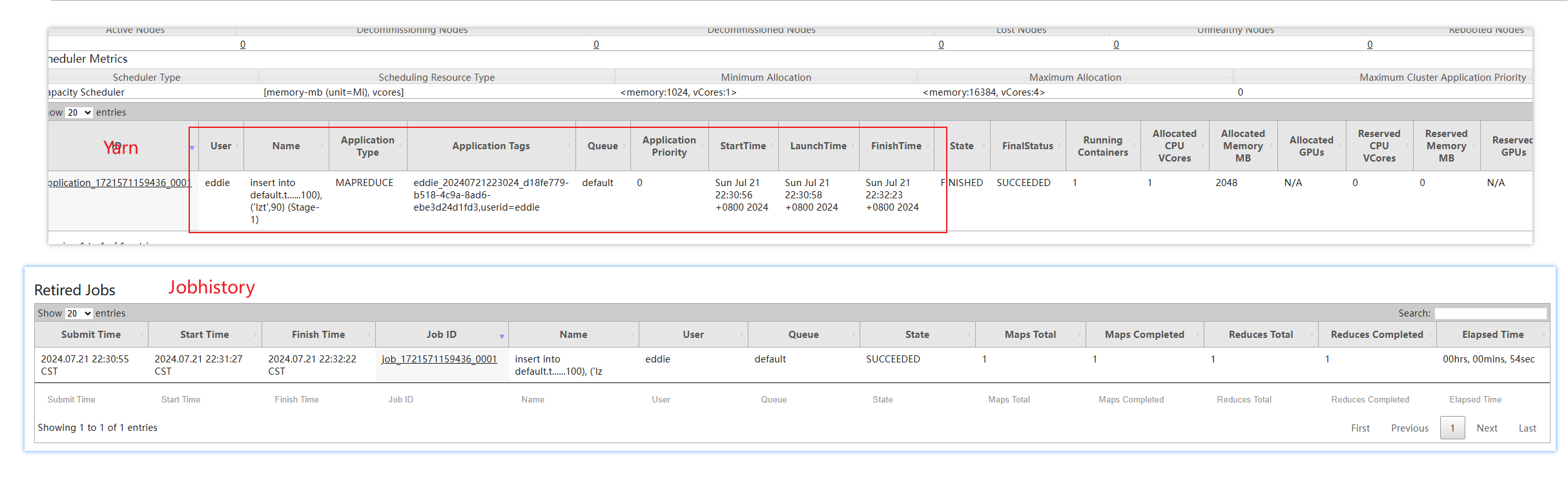
# 4.配置Hive On Spark
hive 4.0.0不支持spark
解释:
Hive 4.0.0 版本确实不支持 Spark。在 Hive 中,数据处理引擎可以是 MapReduce,也可以是 Tez 或者 Spark。在 Hive 4.0.0 之前的版本中,Hive 支持使用 Spark 作为处理引擎,但是在 4.0.0 版本中,这个支持被移除了。
解决方法:
- 降级 Hive 版本到一个支持 Spark 的版本(例如 Hive 3.x)。
- 如果你需要使用 Spark,可以独立于 Hive 使用 Spark,并通过 Spark 连接 Hive 进行数据处理。
- 如果你的应用场景允许,可以使用 Hive 的其他数据处理引擎,如 Tez 或者 MapReduce。
具体采用哪种解决方案取决于你的具体需求和现有的系统环境。
# 解压Spark软件包
cd /opt/softwares/
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/apache/
# 配置环境变量
sudo vim /etc/profile.d/my_env.sh
----------------------------------------------------------------------------
# Spark配置
export SPARK_VERSION=3.5.1
export SPARK_HOME=/opt/apache/spark-3.5.1-bin-hadoop3
export PATH=$SPARK_HOME/bin:$PATH
----------------------------------------------------------------------------
# 切换root分发
su root
xsync /etc/profile.d/my_env.sh
xcall source /etc/profile.d/my_env.sh
# 切回eddie用户
su eddie
# 配置hive中spark配置文件
vim $HIVE_HOME/conf/spark-defaults.conf
----------------------------------------------------------------------------
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bd181:8020/spark-history
spark.executor.memory 4g
spark.driver.memory 2g
----------------------------------------------------------------------------
# 分发
xsync $HIVE_HOME/conf/spark-defaults.conf
# 创建文件夹
hadoop fs -mkdir /spark-history
cd /opt/softwares/
tar -zxvf spark-3.5.1-bin-without-hadoop.tgz -C /opt/softwares/
hadoop fs -mkdir /spark-jars
hadoop fs -put /opt/softwares/spark-3.5.1-bin-without-hadoop/jars/* /spark-jars
# 配置hive on spark
vim $HIVE_HOME/conf/hive-site.xml
----------------------------------------------------------------------------
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://bd181:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
----------------------------------------------------------------------------
xsync $HIVE_HOME/conf/hive-site.xml
# 在bd183启动hive服务
hiveservices.sh start
# 在bd181连接hive
beeline -u "jdbc:hive2://bd183:10000/default" -n eddie -p 密码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
往测试表插入数据,看执行引擎:
insert into default.test values ('zwj',80);
2
# 二、问题
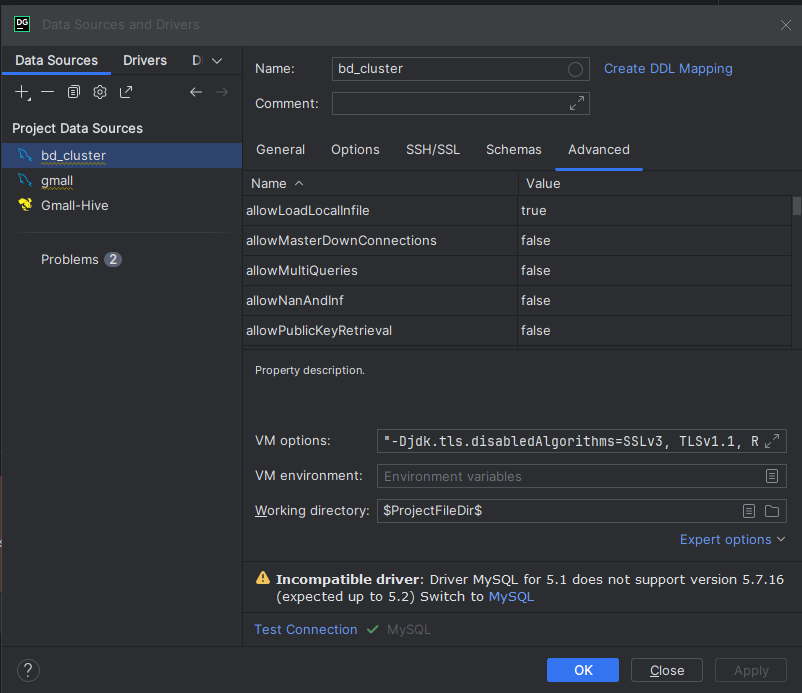
# 问题1:dataGrip连接报错:JDBC driver may have disabled TLS 1.1 and its earlier versions
将VM options的TLSv1改为TLSv1.1:"-Djdk.tls.disabledAlgorithms=SSLv3, TLSv1.1, RC4, DES, MD5withRSA, DH keySize < 1024, EC keySize < 224, 3DES_EDE_CBC, anon, NULL"
# 问题2:User: eddie is not allowed to impersonate anonymous
Error: Could not open client transport with JDBC Uri: jdbc:hive2://bd183:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: eddie is not allowed to impersonate anonymous (state=08S01,code=0)
解决方案:https://kontext.tech/article/303/hiveserver2-cannot-connect-to-hive-metastore-resolutionsworkarounds
把下面配置用户环境打开后正常登录:
vim hadoop-env.sh
# 把下面设置打开
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
xsync hadoop-env.sh
# 切换root用户
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
# 启动hive服务bd183
hive --service metastore
hive --service hiveserver2
# 登录hive
beeline -u jdbc:hive2://bd183:10000 --verbose=true
0: jdbc:hive2://bd183:10000>
show databases;
# 成功
+----------------+
| database_name |
+----------------+
| default |
+----------------+
# 修改配置文件
vim $HADOOP_CONF_DIR/core-site.xml
# 增加以下配置
----------------------------------------------------------------------------
<!--配置eddie(超级用户)允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.eddie.hosts</name>
<value>*</value>
</property>
<!--配置eddie(超级用户)允许通过代理用户所属组-->
<property>
<name>hadoop.proxyuser.eddie.groups</name>
<value>*</value>
</property>
<!--配置eddie(超级用户)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.eddie.user</name>
<value>*</value>
</property>
----------------------------------------------------------------------------
xsync $HADOOP_CONF_DIR/core-site.xml
vim $HADOOP_CONF_DIR/hadoop-env.sh
# 修改以下配置
----------------------------------------------------------------------------
export HDFS_DATANODE_USER=eddie
export HDFS_NAMENODE_USER=eddie
export HDFS_SECONDARYNAMENODE_USER=eddie
export YARN_RESOURCEMANAGER_USER=eddie
export YARN_NODEMANAGER_USER=eddie
export YARN_PROXYSERVER_USER=eddie
#export HADOOP_SECURE_DN_USER=eddie
#export HDFS_DATANODE_SECURE_USER=eddie
----------------------------------------------------------------------------
xsync $HADOOP_CONF_DIR/hadoop-env.sh
# 启动hive服务bd183
hive --service metastore
hive --service hiveserver2
# 用eddie用户登录hive
beeline -u "jdbc:hive2://bd183:10000/default" -n eddie -p 密码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 问题3:Attempting to operate on hdfs namenode as root
ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting resourcemanager ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation. Starting nodemanagers ERROR: Attempting to operate on yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation. [root@bd182 eddie]# mapred --daemon start historyserver
解决:
vim hadoop-env.sh
# 把下面设置打开
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
xsync hadoop-env.sh
2
3
4
5
6
7
8
9
